
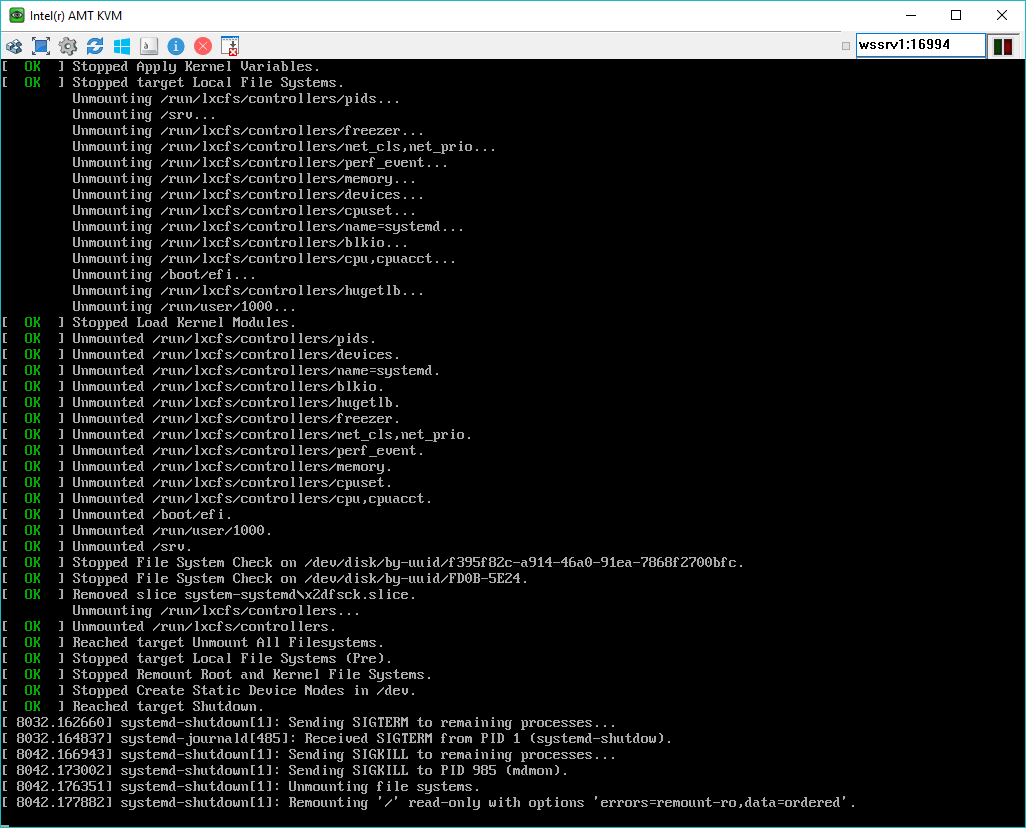
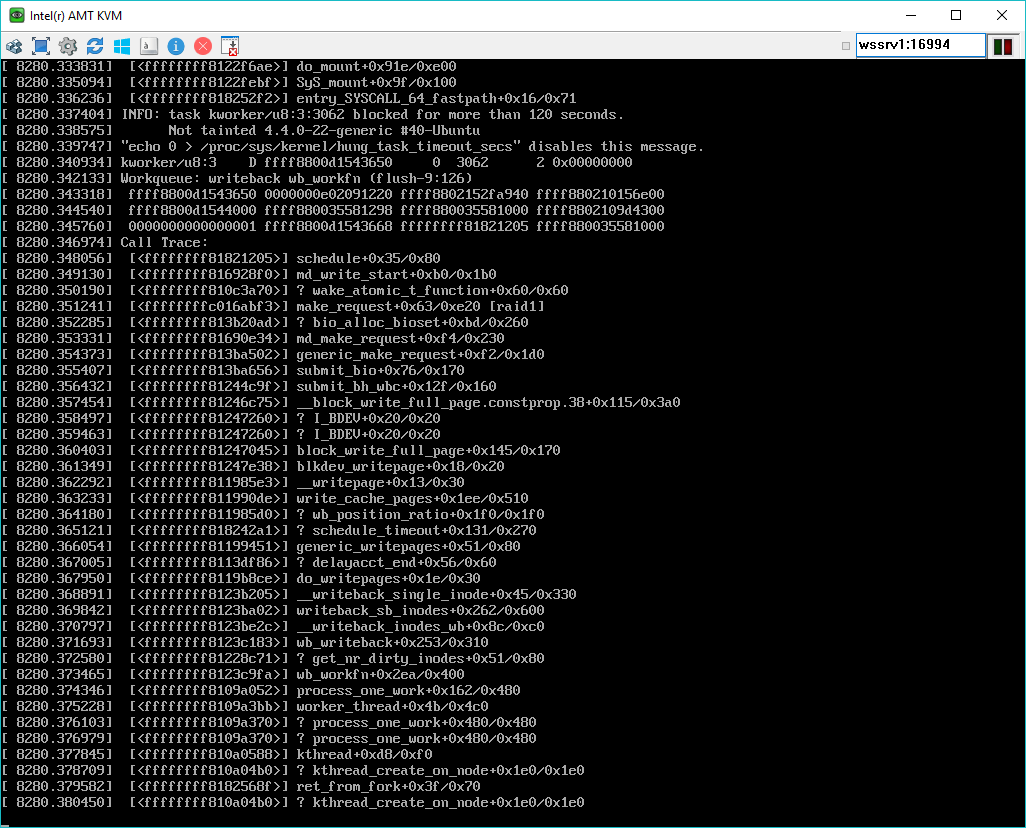
Shutdown hangs in md kworker after "Reached target Shutdown."
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| systemd (Ubuntu) |
Confirmed
|
Critical
|
Dimitri John Ledkov | ||
Bug Description
I'm booting a fully patched 16.04 from an Intel Rapid Storage Technology enterprise RAID1 volume (ThinkServer TS140 with two SATA ST1000NM0033-9ZM drives, ext4 root partition, no LVM, UEFI mode).
If the RAID volume is recovering or resyncing for whatever reason, then `sudo systemctl reboot` and `sudo systemctl poweroff` work fine (I had to `sudo systemctl --now disable lvm2-lvmetad lvm2-lvmpolld lvm2-monitor` in order to consistently get that). However, once the recovery/resync is complete and clean, the reboot and poweroff commands above hang forever after "Reached target Shutdown.". Note that issuing `sudo swapoff -a` beforehand (suggested in the bug #1464917) does not help.
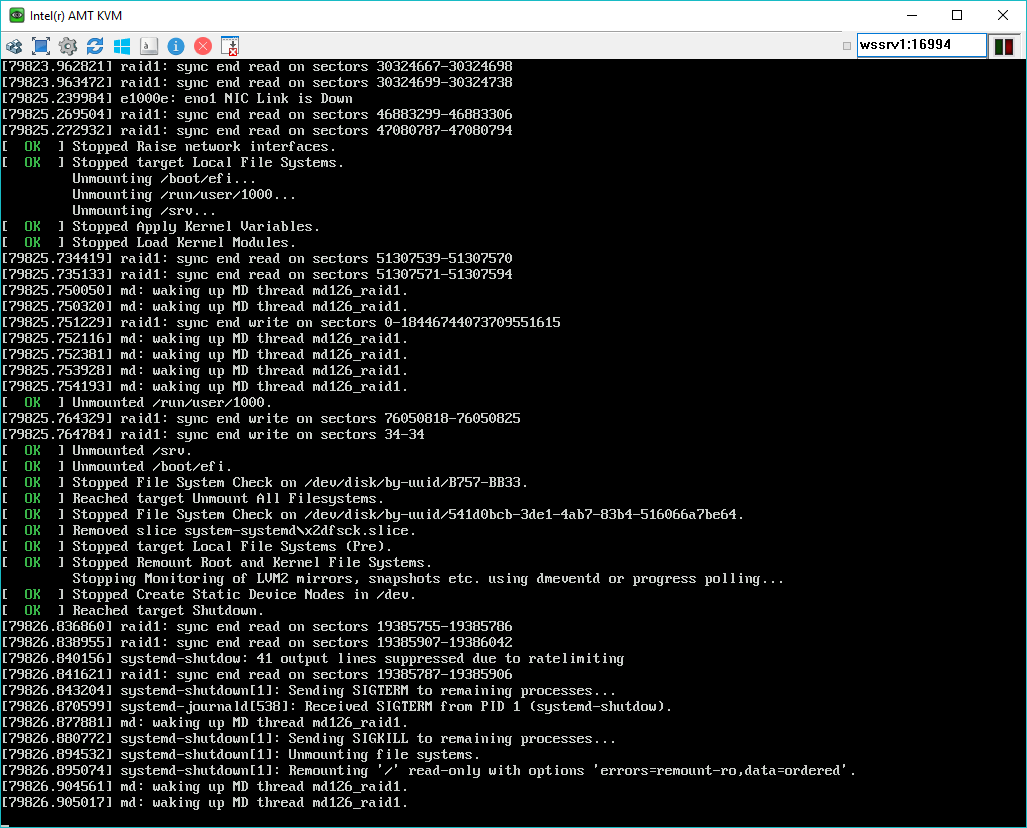
[EDIT]Actually, the shutdown also hangs from time to time during a resync. But I've never seen it succeed once the resync is complete.[/EDIT]
Then, if the server has been forcibly restarted with the power button, the Intel Matrix Storage Manager indicates a "Normal" status for the RAID1 volume, but Ubuntu then resyncs the volume anyway:
[ 1.223649] md: bind<sda>
[ 1.228426] md: bind<sdb>
[ 1.230030] md: bind<sdb>
[ 1.230738] md: bind<sda>
[ 1.232985] usbcore: registered new interface driver usbhid
[ 1.233494] usbhid: USB HID core driver
[ 1.234022] md: raid1 personality registered for level 1
[ 1.234876] md/raid1:md126: not clean -- starting background reconstruction
[ 1.234956] input: CHESEN USB Keyboard as /devices/
[ 1.236273] md/raid1:md126: active with 2 out of 2 mirrors
[ 1.236797] md126: detected capacity change from 0 to 1000202043392
[ 1.246271] md: md126 switched to read-write mode.
[ 1.246834] md: resync of RAID array md126
[ 1.247325] md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
[ 1.247503] md126: p1 p2 p3 p4
[ 1.248269] md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for resync.
[ 1.248774] md: using 128k window, over a total of 976759940k.
Note that the pain of "resync upon every (re)boot" cannot even be a bit relieved thanks to bitmaps because mdadm does not support them for IMSM containers:
$ sudo mdadm --grow --bitmap=internal /dev/md126
mdadm: Cannot add bitmaps to sub-arrays yet
I also get this in syslog during boot when the individual drives are detected, but this seems to be harmless:
May 30 17:26:07 wssrv1 systemd-udevd[608]: Process '/sbin/mdadm --incremental /dev/sdb --offroot' failed with exit code 1.
May 30 17:26:07 wssrv1 systemd-udevd[608]: Process '/lib/udev/hdparm' failed with exit code 1.
May 30 17:26:07 wssrv1 systemd-udevd[606]: Process '/sbin/mdadm --incremental /dev/sda --offroot' failed with exit code 1.
May 30 17:26:07 wssrv1 systemd-udevd[606]: Process '/lib/udev/hdparm' failed with exit code 1.
During a resync, `sudo sh -c 'echo idle > /sys/block/
May 30 18:17:02 wssrv1 kernel: [ 3106.826710] md: md126: resync interrupted.
May 30 18:17:02 wssrv1 kernel: [ 3106.836320] md: checkpointing resync of md126.
May 30 18:17:02 wssrv1 kernel: [ 3106.836623] md: resync of RAID array md126
May 30 18:17:02 wssrv1 kernel: [ 3106.836625] md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
May 30 18:17:02 wssrv1 kernel: [ 3106.836626] md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for resync.
May 30 18:17:02 wssrv1 kernel: [ 3106.836627] md: using 128k window, over a total of 976759940k.
May 30 18:17:02 wssrv1 kernel: [ 3106.836628] md: resuming resync of md126 from checkpoint.
May 30 18:17:02 wssrv1 mdadm[982]: RebuildStarted event detected on md device /dev/md/Volume0
I attach screenshots of the hanging shutdown log after a `sudo sh -c 'echo 8 > /proc/sys/
[EDIT]But I can still switch back to tty1.[/EDIT]
I have also tried with much lower values for vm.dirty_
Linux 4.6.0-040600-
More information below:
$ lsb_release -rd
Description: Ubuntu 16.04 LTS
Release: 16.04
$ uname -a
Linux wssrv1 4.4.0-22-generic #40-Ubuntu SMP Thu May 12 22:03:46 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
$ apt-cache policy systemd
systemd:
Installed: 229-4ubuntu6
Candidate: 229-4ubuntu6
Version table:
*** 229-4ubuntu6 500
500 http://
100 /var/lib/
229-4ubuntu4 500
500 http://
$ cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md126 : active raid1 sda[1] sdb[0]
976759808 blocks super external:/md127/0 [2/2] [UU]
[
md127 : inactive sdb[1](S) sda[0](S)
5288 blocks super external:imsm
unused devices: <none>
$ sudo mdadm -D /dev/md127
/dev/md127:
Version : imsm
Raid Level : container
Total Devices : 2
Working Devices : 2
UUID : e9bb2216:
Member Arrays : /dev/md/Volume0
Number Major Minor RaidDevice
0 8 0 - /dev/sda
1 8 16 - /dev/sdb
$ sudo mdadm -D /dev/md126
/dev/md126:
Container : /dev/md/imsm0, member 0
Raid Level : raid1
Array Size : 976759808 (931.51 GiB 1000.20 GB)
Used Dev Size : 976759940 (931.51 GiB 1000.20 GB)
Raid Devices : 2
Total Devices : 2
State : clean, resyncing
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Resync Status : 5% complete
UUID : 3d724b1d:
Number Major Minor RaidDevice State
1 8 0 0 active sync /dev/sda
0 8 16 1 active sync /dev/sdb
$ sudo mdadm -E /dev/sda
/dev/sda:
Magic : Intel Raid ISM Cfg Sig.
Version : 1.1.00
Orig Family : 92b6e3e4
Family : 92b6e3e4
Generation : 00000075
Attributes : All supported
UUID : e9bb2216:
Checksum : 5ad6e3c8 correct
MPB Sectors : 2
Disks : 2
RAID Devices : 1
Disk00 Serial : Z1W50P5E
State : active
Id : 00000000
Usable Size : 1953519880 (931.51 GiB 1000.20 GB)
[Volume0]:
UUID : 3d724b1d:
RAID Level : 1 <-- 1
Members : 2 <-- 2
Slots : [UU] <-- [UU]
Failed disk : none
This Slot : 0
Array Size : 1953519616 (931.51 GiB 1000.20 GB)
Per Dev Size : 1953519880 (931.51 GiB 1000.20 GB)
Sector Offset : 0
Num Stripes : 7630936
Chunk Size : 64 KiB <-- 64 KiB
Reserved : 0
Migrate State : repair
Map State : normal <-- normal
Checkpoint : 201165 (512)
Dirty State : dirty
Disk01 Serial : Z1W519DN
State : active
Id : 00000001
Usable Size : 1953519880 (931.51 GiB 1000.20 GB)
$ sudo mdadm -E /dev/sdb
/dev/sdb:
Magic : Intel Raid ISM Cfg Sig.
Version : 1.1.00
Orig Family : 92b6e3e4
Family : 92b6e3e4
Generation : 00000075
Attributes : All supported
UUID : e9bb2216:
Checksum : 5ad6e3c8 correct
MPB Sectors : 2
Disks : 2
RAID Devices : 1
Disk01 Serial : Z1W519DN
State : active
Id : 00000001
Usable Size : 1953519880 (931.51 GiB 1000.20 GB)
[Volume0]:
UUID : 3d724b1d:
RAID Level : 1 <-- 1
Members : 2 <-- 2
Slots : [UU] <-- [UU]
Failed disk : none
This Slot : 1
Array Size : 1953519616 (931.51 GiB 1000.20 GB)
Per Dev Size : 1953519880 (931.51 GiB 1000.20 GB)
Sector Offset : 0
Num Stripes : 7630936
Chunk Size : 64 KiB <-- 64 KiB
Reserved : 0
Migrate State : repair
Map State : normal <-- normal
Checkpoint : 201165 (512)
Dirty State : dirty
Disk00 Serial : Z1W50P5E
State : active
Id : 00000000
Usable Size : 1953519880 (931.51 GiB 1000.20 GB)

{kind=link}
{kind=link}
| description: | updated |
| Changed in systemd (Ubuntu): | |
| importance: | Undecided → High |
{kind=link}
| Changed in systemd (Ubuntu): | |
| importance: | High → Critical |
| assignee: | nobody → Dimitri John Ledkov (xnox) |
{kind=link}
The shutdown now also hangs during a resync. So it behaves inconsistently. I update the subject and the description to reflect this.