
Fails to boot when there's problems with softraid
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| mdadm (Ubuntu) |
Triaged
|
High
|
Unassigned | ||
Bug Description
Ubuntu 11.10 has a new feature that it warns you while booting if there's a program with the softraid.
It tells you that a hard disk in the softraid is missing, then asks, on the console:
Continue to boot? y/N
But it ignores all keypresses. After 5 seconds or so it then times out, falls to the default "N" option, and dumps you to a emergency bash prompt, with no indication on how to proceed.
The feature is a good idea, but not in the current broken state.

| JohnFlux (johnflux) wrote : | #1 |
| Dave Gilbert (ubuntu-treblig) wrote : | #2 |
You really want to be able to survive when one of your drives dies; it's not a good time to have to rescue it - so marking high; it'll be a severe impact to a hopefully small percentage
| affects: | ubuntu → dmraid (Ubuntu) |
| Changed in dmraid (Ubuntu): | |
| importance: | Undecided → High |
| Bill Smithem (box3) wrote : | #3 |
This is incorrectly detecting a broken softraid system. Not only does it incorrectly flag a perfectly good working raid setup, it does so without disabling the blank screen that is displayed on std boot, so it appears that the system had hung.
Configuring the system to boot with a "degraded" array lets it boot normally, with the raid fully functional (not degraded) and working correctly.
This is broken.
| Dave Gilbert (ubuntu-treblig) wrote : | #4 |
Bill: I'm not sure that you are describing the same problem; I don't think John's raid was 'a perfectly good working raid' - I think it was a broken one (please correct me John if you believe your RAID was fully intact).
Bill: If it is indeed a separate issue with your RAID incorrectly being detected as broken then please file as a separate bug.
| JohnFlux (johnflux) wrote : Re: [Bug 872220] Re: Fails to boot when there's problems with softraid | #5 |
In my case, it is a mirrored setup, and one disk is missing. So it's
fully functional, but degraded.
| Andrew Nagel (andrew-nagel) wrote : | #6 |
I am having the same issue with some additional information, I have 2 arrays, when one or the other is connected I am getting phantom errors reported on every boot, the boot degraded option gets me past this, but when both array are connected the system is sometimes able to boot and sometimes it fails to mount the arrays.
I have been able to tie both the check failure and the failure to mount degraded to whether the linux_gfx_mode parameter is set to "keep" or "text". It would seem like this has nothing to do with the root issue but I am guessing that the graphics mode is slowing the check down just enough for the drives to report in and pass the test.
Is it possible to disable this check entirely? Beyond the boot degraded option which itself can fail. My system typically sits in a room no keyboard, monitor or anything, if the boot degraded option worked that would be fine, but it doesn't so all this check can do is cause a problem in this scenario.
| Launchpad Janitor (janitor) wrote : | #7 |
Status changed to 'Confirmed' because the bug affects multiple users.
| Changed in dmraid (Ubuntu): | |
| status: | New → Confirmed |
| Phillip Susi (psusi) wrote : | #8 |
I don't think any such feature has been added. I certainly can't find it anywhere. Can you post a screen shot? What normally happens if you don't use the degraded boot argument is that the array will fail to activate. If you have filesystems that can't be mounted at boot, the system asks if you want to continue booting or not, but if your root filesystem is the one that can't be accessed, then you can't actually continue. Is your /etc/fstab pointing to the filesystem by its UUID or the /dev/mapper/xxx device? If it is the raw device, that would explain the system telling you it can't be mounted and not being able to continue.
Just to make sure, I reproduced a mirrored setup in a VM and booted without one of the disks and the system booted right up off the underlying regular disk, bypassing the dmraid since it failed to activate, and the root fs UUID could be seen on the normal disk.
| Changed in dmraid (Ubuntu): | |
| status: | Confirmed → Incomplete |
| Andrew Nagel (andrew-nagel) wrote : | #9 |
I am attaching the dmesg output from a failed boot, unfortunately the mdadm messages don't go to the dmesg log file, I have not been able to find them recorded anywhere but on the screen at this point. The boot dropped into the shell right after the line:
[ 4.201060] md0: unknown partition table
I have found that adding the line:
GRUB_GFXPAYLOAD
allows me to reliably trigger the error. If that line is not present and I am booting after a clean boot (I would assume I could also set it to keep and have the same effect) I can boot without dropping into the shell.
| Andrew Nagel (andrew-nagel) wrote : | #10 |
A follow-up on that comment I am using the bootdegraded=true parameter and each of the two arrays has 5 disks, if I get a full boot all 5 disks come up, it seems like all 10 have just not responded by the time this test comes in and decides it is tired of waiting. I will post dmesg of this in a bit, but triggering these errors, if it can actually create one of the arrays, but halts the boot is now causing problems:
-If the boot is allowed to go through all 10 disks are found and everything comes up cleanly in spite of the errors
-if neither array had made it to 4/5 by the time the check is run and it drops to the shell creating neither array I am fine
-if one of the arrays has made it to 4/5 and one has not, it assembles the 4/5 array and now I need to do a resync once I get my system up cleanly.
It brings up the question to me of why there is not a middle ground option between don't boot at all and boot degraded to just boot and not assemble the array? The current options kind of force someone without physical system access to risk the array just to get the system up.
I will also post an example of a "clean" boot once I get the degraded array from my last error rebuilt.
| Andrew Nagel (andrew-nagel) wrote : | #11 |
- Screen shot 2011-10-22 at 12.15.48 PM.png Edit (74.4 KiB, image/png)
{kind=link}
I was able to reproduce one of the issues in a vmware instance. I am using ubuntu 11.10 server both 64 and 32 bit work fine. Desktop may work as well but I have seen several reports of the initiramfs shell getting blocked by the desktop UI so I through it was simpler to just start without anything graphical.
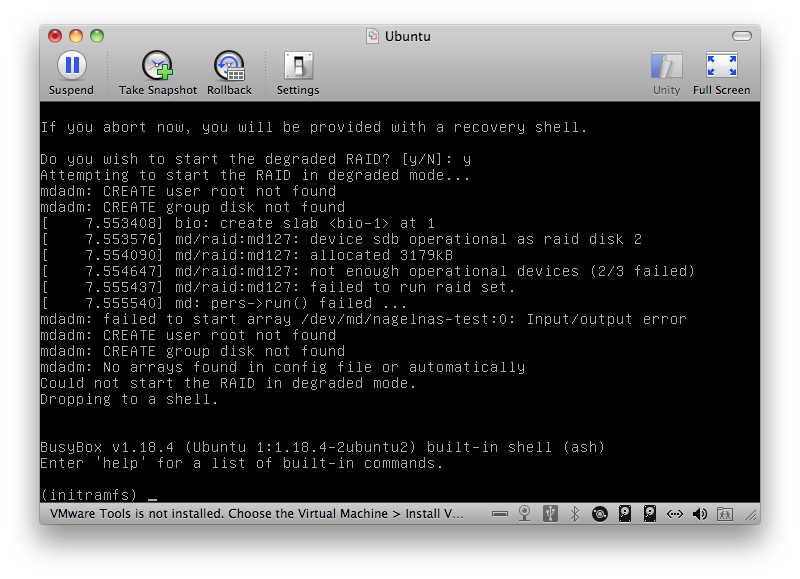
I set up a system with on system drive and 3 small drives. Once up in installed mdadm and created an array from the 3 small drives. I set up a file system added the array to fstab and mdadm.conf, rebooted to make sure everything worked as it should and it did. I shut down the system and disconnected 2 of the 3 drives and booted again. I had forgotten to set the boot degraded option so I had to manually select y when prompted, the system tried to create the array, creation failed and it dropped into the shell. I tried dropping the array from mdadm.conf and that made no difference.
It looks like there is no way to boot a system if it has one disk that reads as being part of a 3+ disk array connected to it. So it looks like there are really 2 separate issues:
(1) if you have a part of an old array or a severely degraded array connected to the system, it is not possible to boot
(2) the point at which the system checks whether this is the case or not happens way too early (for me it happens right after the 4 second mark) and misses disks that might take a while to get up and running (on a clean boot the last of my disks show up around the 5-6 second mark)
the second issue can be worked around if #1 does not exist since the disks are there and by the time the system is fully up all the disks have reported in.
I am attaching a screencap right after it drops into the shell and will also attach the complete dmesg from this error in a separate comment.
| Andrew Nagel (andrew-nagel) wrote : | #12 |
Looks like i didn't grab the output correctly, can run the test again if it would be helpful, but it is similar to the last dmesg only with different drive counts and only a single array, much of it is in the screen cap.
| Andrew Nagel (andrew-nagel) wrote : | #13 |
I also went back and set up the same test on 11.04 and did not experience any issue with boot with only 1 of 3 drives.
| Phillip Susi (psusi) wrote : | #14 |
Ok, mdadm is the package for software raid, dmraid is for fake hardware raid support. Reassigning to the correct package. Also, I tried to reproduce the error in a VM and don't get any prompt about continuing to boot; I just get dropped to the busybox shell, just like in previous Ubuntu versions. Passing bootdegraded=true lets the system boot normally, just as in previous releases. The screen shot I was asking for was for the "continue to boot" prompt, but what you posted just shows the busybox shell.
| affects: | dmraid (Ubuntu) → mdadm (Ubuntu) |
| Changed in mdadm (Ubuntu): | |
| status: | Incomplete → Triaged |
| Andrew Nagel (andrew-nagel) wrote : | #15 |
The message is on the second line visible on the screenshot. Are you testing this with 1 disk of a 3 disk raid5? I am able to reproduce reliably in a vmware fusion instance, if one of three raid discs is attached the system will not boot, drops into intramfs if you say "N" to start degraded and if you say "Y" it tries and fails.
| Andrew Nagel (andrew-nagel) wrote : | #16 |
- Screen shot 2011-10-22 at 10.47.59 PM.png Edit (74.2 KiB, image/png)
{kind=link}
Just reproduced again, better screen grab of the message is attached.
| Andrew Nagel (andrew-nagel) wrote : | #17 |
- Virtual Disk 5.vmdk Edit (489 bytes, text/plain)
Some more info, for me at least, just attaching the attached disk to a fusion instance of 11.10 makes it unbootable, the only way I have found to get it bootable is to remove the disk. Like I said the effect would seem to be it is impossible to put a disc that has at some time in the past been a part of a RAID5 array into a system even if all you want to do is format it.
| Andrew Nagel (andrew-nagel) wrote : | #18 |
A potential solution to one of the two problems effecting the raid boot has been posted on one of the discussion threads on the topic: http://
This does nothing to effect the poison pill bug with rad5 but it should at least make it so the problem only occurs when there is actually a degraded array, or a random disk from an old array in the system and not for perfectly healthy arrays.
| DooMMasteR (winrootkit) wrote : | #19 |
I have one HDD with 11.10 installed on and booting fine.
If I now connect a disk which is part of a RAID the boot fails with mdadm complaining about a degraded root.
This is not satisfying as the RAID is not needed to boot the system, and the system hangs during boot when it was uncontrolled powered down.This makes it impossible to run the machine unattended.
In 10.04 and 10.11 the solution was more satisfying as the system would boot just fine but mark all HDDs of the RAID it found as SPARE and not activate it thusly the system booted just fine and just failed to activate the RAID.
I found some solutions but all would break on an unattended update (initramfs or kernel) and thusly again are not satisfying.
Is there a simple solution to make the system boot just fine as it did before in 10.04 and 10.11 and does not break with updates or break the updates themselves?
| DooMMasteR (winrootkit) wrote : | #20 |
passing 'bootdegraded=true' is no solution
so far I have found no way to boot my system.
As long as a disk which is part of an incomplete RAID is connected I will always end up in a BusyBox recovery shell, one way or another.
this is really annoying and can by far not be an intended feature…
it also does not matter if the RAID is included in mdadm.conf or if it is completely empty
I would understand this way of problem handling if the RAID contained essential data and was needed, but it will never be mounted during bootup and also is not contained in fstab, it is as if a broken device just prevents your system from bootup (in fact any USBthumbdrive with a Superblock describing it as part of a large RAID will do that)
I can obviously just disconnect my disks but that is not the case if the machine is unattended and had to reboot for one reason or another, when the RAID is not synced it will just fail to boot (there would not even be sshd running to offer remote access)
we had that situation before and I could then force assemble the RAID remotely but only because 10.04 would boot even with an degraded RAID attached
| Clint Byrum (clint-fewbar) wrote : | #21 |
So far everything I've read beyond the original description shows mdadm working as it is intended.
The question on whether or not to boot degraded is not just about the root filesystem. The idea is to be very careful and not boot with *any* disks in a degraded array, as we want to avoid the corruption problem possible because of bug #557429. If you were to accidentally boot w/o one of your disks, we want to confirm with you that this was your intention. We are favoring safety of data over convenience.
You can set your system to boot degraded permanently with
sudo dpkg-reconfigure mdadm
And answer yes to the question.
As to the original complaint, I do see merit in explaining *what* you might do if you say "N". However, we don't have a friendly way to help the user recover their arrays, so directing them to mdadm may also be fairly scary. I'm open to suggestions as to what we might want to display there, but I don't think this is a bug in behavior, just a usability problem.
| Andrew Nagel (andrew-nagel) wrote : | #22 |
Clint the issue is that it does this regardless of whether the device is a boot device or not and this makes the system unbootable if you have 1 disk from a RAID 5 array attached to it.
1. Set boot degraded to false, result: you get a prompt asking if you want to try boot degraded
1.a Answer no, it drops you into the debug shell
1.b Answer yes, assemble degraded fails, it drops you into a the debug shell
2. Set boot degraded to true, result system tried to attach the degraded array, assemble fails, system drops into the debug shell.
| Andrew Falconer (jam-x) wrote : | #23 |
Had an extremely frustrating experience with this bug while attempting to re-install a Debian system with Ubuntu 12.02 x86_64, and while trying to debug 11.10. The main issue was that by the time I was dropped to a shell the prompt asking if I wanted to boot degraded was long and gone from my scroll back and covered with mdadm output - the only evidence that something was up was a "Timed Out" message with no context.
Although the install was onto a single non-raided drive, and there were no file systems in /etc/fstab located on raid devices I experienced constant hanging on boot as there were other non-system disks present which were members of a RAID5 array which was unable to start. After finally tracking this down the easiest out was to modify /usr/share/
I would suggest that rather than timing out and dropping to a shell the best default option would be to simply not start the array at all, display a message to that effect, and let the user deal with the issue if the system is able to boot.
If the system is not able to boot due to the raid array holding a system volume and there are concerns about allowing arrays to start degraded by default it is more reasonable to at least continue booting and hit an error, such as failed to mount / (which would probably drop them to a shell anyway), rather than stopping the boot process altogether.
| draco (draco31-fr) wrote : apport information | #24 |
ApportVersion: 2.0.1-0ubuntu7
Architecture: amd64
DistroRelease: Ubuntu 12.04
MDadmExamine.
/dev/sda:
MBR Magic : aa55
Partition[1] : 65496942 sectors at 63 (type 05)
Partition[2] : 325219860 sectors at 65497005 (type fd)
MDadmExamine.
/dev/sda2:
MBR Magic : aa55
Partition[0] : 65496879 sectors at 63 (type 83)
MDadmExamine.
/dev/sdb:
MBR Magic : aa55
Partition[1] : 65496942 sectors at 63 (type 05)
Partition[2] : 325219860 sectors at 65497005 (type fd)
MDadmExamine.
/dev/sdb2:
MBR Magic : aa55
Partition[0] : 65496879 sectors at 63 (type 83)
MDadmExamine.
/dev/sdc:
MBR Magic : aa55
Partition[1] : 73062337 sectors at 63 (type 05)
Partition[2] : 325219860 sectors at 73063620 (type fd)
MDadmExamine.
/dev/sdc2:
MBR Magic : aa55
Partition[0] : 73060289 sectors at 2048 (type 83)
MDadmExamine.
/dev/sdd:
MBR Magic : aa55
Partition[0] : 24576000 sectors at 2048 (type 83)
Partition[1] : 36864000 sectors at 24578048 (type 05)
Partition[2] : 63602688 sectors at 61442048 (type 83)
MDadmExamine.
MDadmExamine.
/dev/sdd2:
MBR Magic : aa55
Partition[0] : 6144000 sectors at 2048 (type 82)
Partition[1] : 24576000 sectors at 6146048 (type 05)
MDadmExamine.
MDadmExamine.
MDadmExamine.
MDadmExamine.
MDadmExamine.
/dev/sde:
MBR Magic : aa55
Partition[0] : 1953520002 sectors at 63 (type 83)
MDadmExamine.
MDadmExamine.
/dev/sdf:
MBR Magic : aa55
Partition[0] : 625137282 sectors at 63 (type 83)
MDadmExamine.
MDadmExamine.
/dev/sdg:
MBR Magic : aa55
Partition[0] : 39061504 sectors at 2048 (type 83)
Partition[1] : 8787968 sectors at 232466432 (type 82)
Partition[2] : 193402880 sectors at 39063552 (type 83)
MDadmExamine.
MDadmExamine.
MDadmExamine.
| tags: | added: apport-collected precise |
| draco (draco31-fr) wrote : BootDmesg.txt | #25 |
| draco (draco31-fr) wrote : CurrentDmesg.txt | #26 |
| draco (draco31-fr) wrote : Dependencies.txt | #27 |
| draco (draco31-fr) wrote : Lspci.txt | #28 |
| draco (draco31-fr) wrote : Lsusb.txt | #29 |
| draco (draco31-fr) wrote : MDadmExamine.dev.sda3.txt | #30 |
| draco (draco31-fr) wrote : MDadmExamine.dev.sda5.txt | #31 |
| draco (draco31-fr) wrote : MDadmExamine.dev.sdb3.txt | #32 |
| draco (draco31-fr) wrote : MDadmExamine.dev.sdb5.txt | #33 |
| draco (draco31-fr) wrote : MDadmExamine.dev.sdc3.txt | #34 |
| draco (draco31-fr) wrote : MDadmExamine.dev.sdc5.txt | #35 |
| draco (draco31-fr) wrote : ProcCpuinfo.txt | #36 |
| draco (draco31-fr) wrote : ProcInterrupts.txt | #37 |
| draco (draco31-fr) wrote : ProcMDstat.txt | #38 |
| draco (draco31-fr) wrote : ProcModules.txt | #39 |
| draco (draco31-fr) wrote : ProcMounts.txt | #40 |
| draco (draco31-fr) wrote : ProcPartitions.txt | #41 |
| draco (draco31-fr) wrote : UdevDb.txt | #42 |
| draco (draco31-fr) wrote : UdevLog.txt | #43 |
| draco (draco31-fr) wrote : etc.blkid.tab.txt | #44 |
| draco (draco31-fr) wrote : initrd.files.txt | #45 |
| draco (draco31-fr) wrote : mdadm.conf.txt | #46 |
| draco (draco31-fr) wrote : | #47 |
Hi,
In my experience, one device used in an md array has been renumbered after upgrading from oneiric to precise.
At the first reboot, I've got the message 'Continue boot y/N' but can't enter anything.
After few seconds, I've got a busybox/initramfs prompt on TTY1, but without any further informations for misassembled array.
CTRL+D at prompt give me access to a root terminal so I can rename mdadm.conf and comment md array in fstab.
I do that because it was the last messages in dmesg but there was no warning about devices not found.
So, system boots fine, and then I could manualy :
- change mdadm.conf to reflect the change of named device/partition ( sdc --> sda).
- update initramfs and active mount in fstab.
I never though that making a 'simple' dist-updgrade could leave the system un-bootable without such admin (geek) skills !!
Maybe a kind of warning can be added on release notes for people using softraid.
| Phillip Susi (psusi) wrote : | #48 |
draco, you seem to misunderstand the purpose of this bug. It deals with booting with a failed disk, not problems upgrading distributions.
| draco (draco31-fr) wrote : Re: [Bug 872220] Re: Fails to boot when there's problems with softraid | #49 |
I agree. The fact my device has been renumbered is not relative to this
bug, and also not directly relative to the upgrade.
If I understand well, you complain about the fact ubuntu won't boot with a
degraded array and don't allow any possibility to continue the boot process
without mounting the array.
Mainly because we can't enter an answer to the message on the splash screen.
This is about that problem, I propose my apport infos.
If I misunderstand the problem you are reporting for, please, let me know.
draco
Le 8 mai 2012 19:28, "Phillip Susi" <email address hidden> a écrit :
> draco, you seem to misunderstand the purpose of this bug. It deals with
> booting with a failed disk, not problems upgrading distributions.
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> Fails to boot when there's problems with softraid
>
> To manage notifications about this bug go to:
> https:/
>
| Phillip Susi (psusi) wrote : | #50 |
Oh, so you also have a failed disk?
| draco (draco31-fr) wrote : | #51 |
Not realy. I have multiple disk, and as they renumbered, mdadm tries to
assemble the arrays with the wrong disk so it can't.
The disk is not marked as faulty, but the arrays are not assembled.
I think mdadm could not do anything more as the hole system is read only at
this stage. So when i could repair the mdadm.conf, the arrays don't need to
be rebuild on the disk, as they were never started in read-write mode with
a missing device.
Do you mean that ubuntu is responsible for marking your disk as faulty? I
was thinking you are just reporting the side effect of this situation on
the boot process of ubuntu.
draco
Le 10 mai 2012 03:01, "Phillip Susi" <email address hidden> a écrit :
> Oh, so you also have a failed disk?
>
> --
> You received this bug notification because you are subscribed to the bug
> report.
> https:/
>
> Title:
> Fails to boot when there's problems with softraid
>
> To manage notifications about this bug go to:
> https:/
>
| Krzysztof (chrisk4) wrote : | #52 |
I'm experience the same issue, having 2 disk in soft RAID when one fails trying replace it and booting into normal mode i'm unable to input 'y' after question of booting into degraded mode (strange enough i've boot degraded set to true!)
But i'm able to boot to system and rebuild raid when choice-ing recovery mode on working drive (remains of my degraded array)
Then i'm able to rebuild array and start system correctly... But it requires time and during rebuild other services are unaccesible - in version 10.04 i was able to boot into normal mode with degraded partition and rebuild RAID on working system
Regards
| Anders Logg (logg) wrote : | #53 |
I'm experiencing the same problem. I've recently installed a fresh copy of 12.04 on my home server and created a RAID 1 array with two identical disks using the disk utility for data storage (boot, system, home directories on other separate disks).
To try out my RAID array, I shut down and remove the cables, then boot. I expect the RAID to magically mount (I have it in fstab) and let me write some data to the partition. After rebooting with the cables back in, I expect it to magically sync the disks... (But maybe that is hoping too much?)
What happens instead is that the system fails to boot and I get thrown into a busybox shell, even if the system/boot is on an entirely different disk. This happens even if I add 'noauto' in fstab for the RAID partition.
| nanog (sorenimpey) wrote : | #54 |
Whoever marked this bug: https:/
In ubuntu 12.04 there is a major regression in mdadm where a delay in registration of RAID component (by udev) during init results in an array being MISTAKENLY tagged as corrupt. This drops the server into a busy box shell and prevents remote restart. This is a MAJOR regression.
Please, please unmark 917520 as duplicate. And those of you who have posted on this bug with symptoms described in 917520 should confirm on the other bug.
Fortunately, there is a solution that is known to fix this bug as described here:
http://
| vak (khamenya) wrote : | #57 |
try mdadm-3.2.5-1ubuntu from PPA. It seems to help me
| Dimitri John Ledkov (xnox) wrote : | #58 |
On 16/07/12 08:40, vak wrote:
> try mdadm-3.2.5-1ubuntu from PPA. It seems to help me
>
Please do not use PPAs, but wait for a fix to be applied in
precise-proposed.
--
Regards,
Dmitrijs.
| Leonardo Silva Amaral (leleobhz) wrote : | #59 |
My case happened with 12.04: I almost never reboot my machine and since ive installed it, i never rebooted until now. i fall into a degraded state without possibility to boot in degraded mode and even using super grub disk to set the bootdegraded=true. Array start in read only mode and notting in the world make it start restoring in console.
But using Quantal test version this happens:
root@wall-e:~# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md125 : active (read-only) raid1 sda[1] sdb[0]
104857600 blocks super external:/md127/0 [2/2] [UU]
md126 : active raid0 sda[1] sdb[0]
1743800320 blocks super external:/md127/1 128k chunks
md127 : inactive sda[1](S) sdb[0](S)
5024 blocks super external:imsm
unused devices: <none>
root@wall-e:~# mdadm -S -s
mdadm: stopped /dev/md125
mdadm: stopped /dev/md126
mdadm: stopped /dev/md127
root@wall-e:~# mdadm -A -R -f -s
mdadm: Marking array /dev/md/imsm0 as 'clean'
mdadm: Container /dev/md/imsm0 has been assembled with 2 drives
mdadm: Started /dev/md/LVM_0 with 2 devices
mdadm: Started /dev/md/RootFS_0 with 2 devices
root@wall-e:~# cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md125 : active raid1 sda[1] sdb[0]
104857600 blocks super external:/md127/0 [2/2] [UU]
[
md126 : active raid0 sda[1] sdb[0]
1743800320 blocks super external:/md127/1 128k chunks
md127 : inactive sdb[1](S) sda[0](S)
5024 blocks super external:imsm
unused devices: <none>
Im a lot afraid about data loss because even before the resync finish, i got this:
<A LOT OF MESSAGES EQUAL NEXT LINE, CHANGING INODE NUMBER>
[ 1102.993890] EXT4-fs (md125p1): ext4_orphan_
[ 1102.993903] EXT4-fs (md125p1): 7558 orphan inodes deleted
[ 1102.993904] EXT4-fs (md125p1): recovery complete
[ 1104.169317] EXT4-fs (md125p1): mounted filesystem with ordered data mode. Opts: (null)
And i dont know what to do. I will wait this restore and attempt to reboot.
| Simon Bazley (sibaz) wrote : | #60 |
I submitted this in reference to 990913 but now think that relates to the mdadm/udev racing condition discussed in 917250. My issue is that a attached, degraded, devices which should not be required, are preventing my setup from booting:-
I have a similar problem, but suspect the issue I'm having means it must be either down to code in the kernel or options unique to my ubuntu/kernel config, or something in my initramfs. /proc/version reports: 3.2.0-30-generic.
In my case, I have 5 disks in my system, 4 are on a backplane, connected directly to the motherboard, and the 5th is connected where the cd should be.
These come up on linux as /dev/sd[a-d] on the motherboard and /dev/sde on the 5th disk.
I have uinstalled the OS entirely on the 5th disk, and configured grub/fstab to identify all partitions by UUID. fstab does not reference any disks in /dev/sd[a-d].
The intention being, to install software raid on the a-d disk, to present as /dev/md0
I created a RAID5 array with 3+spare, and one of the disks died. So I have a legitimated degraded array, which the OS should not need to boot.
However it won't boot either with 'bootdegraded=true' or not
Not sure editing mdadm functions will help as really I don't want any md functions to run at initramfs time. They can all wait until after it's booted.
Any thoughts on how I can turn off mdadm completely from initramfs?
| Simon Bazley (sibaz) wrote : | #61 |
I thought it helpful to link to https:/
It's stating the obvious but I found I could boot normally with degraded softraid disks by uninstalling mdadm, which removes the mdadm scripts from the /usr/share/
I'll try to find a fix for my problem, by hacking about with the mdadm scripts added to initramfs-tools, but suspect this issue is best tied to the mdadm package, where said scripts originate.
| Simon Bazley (sibaz) wrote : | #62 |
sorry bad link, try https:/
| Simon Bazley (sibaz) wrote : | #63 |
A quick hint, to those that didn't know (like me) at the (initramfs) prompt, if the failed raid array isn't needed to boot, then you can simply type return 0 to have it continue normally with the boot
| Simon Bazley (sibaz) wrote : | #64 |
Ok, think I've fixed this. I've changed the /usr/share/
Then I've extended the /usr/share/
If either the list of required devices is empty, or none of the degraded devices match anything in the file, then the degraded_
Finally I've changed /usr/share/
I'll post a unified diff patch as the next comment.
| Simon Bazley (sibaz) wrote : | #65 |
diff -u -r initramfs-
--- initramfs-
+++ initramfs-
@@ -61,12 +61,112 @@
done
# copy the mdadm configuration
+FSTAB=/etc/fstab
CONFIG=
ALTCONFIG=
DESTMDADMCONF=
+BOOTREQDDRIVES
[ ! -f $CONFIG ] && [ -f $ALTCONFIG ] && CONFIG=$ALTCONFIG || :
mkdir -p ${DESTDIR}
+is_md_device()
+{
+ # --misc --detail will only return OK for active arrays
+ mdadm --misc --detail $1 >/dev/null 2>&1
+ ACTIVE=$?
+ # --misc --examine will only return OK for inactive arrays
+ mdadm --misc --examine $1 >/dev/null 2>&1
+ INACTIVE=$?
+ return $((${ACTIVE} & ${INACTIVE}))
+}
+
+find_inactive_
+{
+ # mdadm --misc --scan --examine returns a list including inactives, but uses the form /dev/md/0 instead of /dev/md0
+ scanname=`echo $1 |sed "s/\(\/
+ mdadm --misc --scan --examine 2>/dev/null|grep ${scanname} | while read array device params; do
+ uuid=${
+ echo ${uuid}
+ return 0
+ done
+ return 1
+}
+
+log_details_
+{
+ #echo "Seems $1 is an md device"
+ mduuid=`mdadm --misc --detail $1 2>/dev/null|grep UUID|sed "s/^.*UUID : \([:a-z0-
+ if [ "${mduuid}" = "" ] ; then
+ mduuid=
+ fi
+ if [ "${mduuid}" != "" ] ; then
+ echo "Identified, md device $1, identified by UUID ${mduuid}, as required in fstab. "
+ echo $1 >> ${BOOTREQDDRIVES}
+ echo ${mduuid} >> ${BOOTREQDDRIVES}
+ return 0
+ else
+ #echo "Couldn't work out the uuid for md device $1"
+ return 1
+ fi
+}
+
+
+identify_
+{
+ #echo "Identifying $1"
+ #Device identified as a valid device, so lets see if it is an md device
+ if is_md_device $1; then
+ #echo "$1 is an md_device"
+ # It is an md device, so try to log important details, for next boot
+ if ! log_details_
+ # Something went wrong identifying device details, so just log what we can
+ echo "Had issues identifying details for md_device $1"
+ if ! grep -q $1 ${BOOTREQDDRIVES}; then
+ echo $1 ${BOOTREQDDRIVES}
+ fi
+ fi
+# else
+# echo "$1 is not an md_device"
+ fi
+}
+
+# PARSE FSTAB to get a list of md file_systems essential for boot
+rm -f ${BOOTREQDDRIVES}
+touch ${BOOTREQDDRIVES}
+cat ${FSTAB} | grep -v ^\# | while read file_system mount_point type options dump pass; do
+ if [ "${pass}" = "" ] ; then
+ pass=0
+ fi
+ if [ ${pass} != 0 ] ; then
+ ...
| Dimitri John Ledkov (xnox) wrote : | #66 |
Please explain how you deduce boot_required list in the case of lvm on top of crypt on top of mdadm raid device?
| Dimitri John Ledkov (xnox) wrote : | #67 |
@ Comment 59 Leonardo Silva Amaral (leleobhz)
It looks like you are using external metadata (isms) instead of Linux Raid format. Booting of isms raid volues with mdadm is currently not supported. You can/should use dmraid instead, until mdadm/isms support is integrated into initramfs-tools. There is a bug open about it.
| Dimitri John Ledkov (xnox) wrote : | #68 |
The current design is:
* if a disk is really not present and the array is truly degraded, we should not boot unless boot_degraded is true
* if disks are actually present and healthy, yet the array is detected as degraded => please file a new bug about your case, it should be fixed.
The reason is that there is disagreement whether it is safe to boot in degraded mode automatically, because currently we have no default ways of notifying the administrator that raid is degraded.
There is dataloss potential: boot once degraded of sda, another time of sdb. Boot with both => syncing can lead to data loss.
| Simon Bazley (sibaz) wrote : | #69 |
boot_required is simply deduced by interrogating fstab, to find mount points which are 'required' to boot, (ie have a pass value not 0).
The script logs anything (and all) of the strings which it thinks might enable it to identify at boot time, a device which might be subsequently required. Currently, that means the device name and the UUID returned from mdadm when a device given, returns a device either with mdadm --misc --detail <device> or mdadm --misc --explain <device>
If fstab identification only comes up with a /dev/mapper/
In my setup, I don't use lvm, so I've considered it.
My concern is that if 'a disk is really not present', so an array 'is truely degraded', that we should not boot, that effectively means that mdadm is not compatible with remote servers, that use soft raid, on non-essential disks, as an error which could be repaired by a remote opporater, will effectively prevent the server from rebooting. It is that, which I am seeking to avoid.
Clearly changes made to fstab after update-initramfs has been run, won't be included in the boot_required file, but as the alternative, in my production environment is having to uninstall mdadm, this seemed an imperfect improvement.
That said, it would probably be a better course, to include a boot option, boot_degraded=
I do accept that it is wise to default, to not booting, when arrays are degraded. But there must be a configurable option to an alternative. In your example, my suggested change would detect that the sda/sdb array was 'required' and log the uuid for it to boot_required. Booting to sda with that array degraded, would be picked up as in boot_required, and fall to an initramfs shell. It is just not a valid assumption that any degraded array, will cause data loss. If an operator knows it won't they should be able to configure that.
| Nick Stuckert (nickstuckert) wrote : | #70 |
Since it has been a year, and nobody has even been assigned to this problem, please consider marking this severe.
This is completely unbelievable. Somebody not competent enough broke the debian raid setup for ubuntu years ago, and the issues has still not been resolved?
Man, fix up ubuntu mdadm to issue proper notifications (bug #535417). Get rid of that bogus boot_degraded question (bug #539597), and finally implement a reliable raid.
@simon: good job! Maybe the notes about the required dependencies in https:/
What a mistake to assume improvements in ubuntu raid and retry. Instead, use a debian installation.
| Michael Basse (michael-alpha-unix) wrote : | #73 |
still facing this bug, see also
https:/
The mainproblem for me is that the keyboard is not working there, i can not press "y" to say "boot it anyway".
| ianfas (ianfas) wrote : | #74 |
I'm also facing this bug.
My problem is the same as Michaels:
"The mainproblem for me is that the keyboard is not working there, i can not press "y" to say "boot it anyway"."
This is very annoying.
| Andreas Wuttke (a-wuttke) wrote : | #75 |
Please fix at least the default behavior. The system must start up with a degraded raid whenever possible without the need to answer questions during system startup.
As mentioned above several times the current implementation doesn't work and compromises the good impression the Ubuntu Server edition gave so far.
| Mathias Burén (mathias-buren) wrote : | #76 |
I updated the kernel on my 32-bit 12.10 setup, just to find out that it won't boot due to the symptoms described in this bug report. I tried compiling my own 3.8.5 from kernel.org, but the results are the same. I can't use the keyboard, even though kernel messages are displayed about USB keyboard HID when I re-plug the keyboard. bootdegraded=true only drops me to initramfs, not exactly helpful.
My array is not degraded, so I'm not sure what this is about.
| M. O. (marcusoverhagen) wrote : | #77 |
I just made a full update on a 180 days old 12.04.2 system. Everything was fine before, but on reboot I'm dropped into this rescue shell, because /dev/sdc1 is detected as belonging to a degraded raid.
However, the raid is not degraded! cat /proc/mdstat shows it as healty (keyboard is working), and after I type exit boot continues normally.
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md127 : active raid5 sdk1[8] sdj1[10] sdm1[5] sdi1[3] sdh1[4] sdg1[1] sdl1[9] sdc1[11]
13674582656 blocks super 1.2 level 5, 64k chunk, algorithm 2 [8/8] [UUUUUUUU]
bitmap: 1/466 pages [4KB], 2048KB chunk
unused devices: <none>
| JazZ (misterj-home) wrote : | #78 |
I am very shocked. I just had a disc (between RAID 5) which crashes, and you are saying me, that it is not possible to boot and to access data ? During the install (ubuntu 13.10), I have selected boot degraded, and the system does not boot. Black screen, no error message, no shell command after 20 minutes, and no initramfs. I can't do anything. I don't understand this logic to say that it is preferable to not boot in order to prevent data loss it it is not possible to mount the system. So my data is protected, but I can access to it !
Shameful for a bug declared 1.5 years ago, and for a so critical bug !
Why have you not desactivated the ubuntu raid install since the bug is not corrected ?
The only chance I have is to have preserved my older server and than a part of my data.
| M. O. (marcusoverhagen) wrote : | #79 |
For those that have this problem with a non-degraded raid mistakenly marked as degraded, please see/subscribe https:/
@Marcus Overhagen: Thanks for your message. You may update the ReliableRaid wiki page.
I found it worthwhile that I migrated my raid systems to debian, now I am doing the same with the debian desktop howto, and welcoming the debian tanglu project.
| CvB (cvb-kruemel) wrote : | #81 |
For what it's worth: Just had the same issue with Ubuntu 12.04:
"The mainproblem for me is that the keyboard is not working there, i can not press "y" to say "boot it anyway"."
This is very annoying.
I can continue boot by typing "return 0" into the maintenance console. But there is no way to keep the server automatically booting. Even "bootdegraded=true" does not help.
This is very, very annoying.
| Joshua McKinney (joshka-launchpad) wrote : | #82 |
Still a problem in Saucy (13.10) beta
| Davias (davias) wrote : | #83 |
I was dropped to busybox on my RAID1 Ubuntu 12.04 AMD64 system uptodate. cat /proc/mdstat reported [U_] on all 3 md devices (/, swap & /home), but I was pretty sure the disk (sdb) was functional.
On reset I pressed ESC to get to the grub menu to select rescue, I could see the message "array degraded press Y to boot degraded" but could not, it automaticcally selected N and drop me again into busybox. From there I could resync the array manually with:
mdadm --add /dev/md0 /dev/sdb1
waited for the md0 to resync and checked again with cat /proc/mdstat that md0 was ok. Repeated the operation for md1 and checked, then md3 and checked again that all MD devices were [UU] good. Reset and the system came up OK!
I then checked extensively disk sdb with SMART that reported no errors and no bad sectors. Did a surface test: ok; a fsck, ok.
So, bottom line, array went out of sync for no apparent reason, and could not start degraded...
Any ideas?
| Lek (k-lek) wrote : | #84 |
Had som "holiday-fun" with my debian-server and installed the Trusty14.04 alfa (is qurious about the clouds).
Sadly the same bug bit me, albeit on some old lazy 250G disks. my OCZ revodriveX2 is apparently still fast enough to not lose out in this racecondition.
https:/
found som excellent reading on https:/
Reinstalld debian 6 just to try and it has not the same behaviour = softraid on the same disks works.
My earlier experiences of RAID quirks is limited to SCSI and "real" RAID-adapters so this was a chanse to read up on some good documentation. And see again that "when you fix what isn't broken you get a lot of "new" work".
Yes I'm old ;)
| terminal2000 (terminal2000) wrote : | #85 |
This whole automatic recovery mode by default is such a BUG, NOT A FEATURE. Please rollback.
Most of the servers with RAID on this planet are headless. Stuck in the boot process by any means is asking for trouble. If it doesn't boot, then there's no easy way to fix anything not to mention "recover".
What the boot process should do is to work its ass off to make the system boot, no matter what. If some RAID is degraded, let it be and just don't mount it automatically.
There's no f**king any reason to stop booting just because some f**king data disk is not able to mount. Boot it with that one unmounted, whatsoever.
| Nolodude (nolodude) wrote : | #86 |
So yeah, a three-year old bug cut me off from my headless server today. Awesome.
The default behaviour to require actual user interaction in case of degraded RAID array is just ... wrong. It's SO MUCH MORE important to get the system up and running so we can diagnose and fix the problems. You can't fix RAID problems in initframs, and you also can't add the option "bootdegraded=true" to Grub in initframs.
Could somebody please fix this.
As a workaround, you can add "bootdegraded=true" to the kernel boot options.