
IPv6 related kernel panic following upgrade to 3.13.0-43
Bug #1404558 reported by
Stéphane Graber
This bug affects 7 people
| Affects | Status | Importance | Assigned to | Milestone | |
|---|---|---|---|---|---|
| linux (Ubuntu) |
Invalid
|
Critical
|
Andy Whitcroft | ||
| Trusty |
Fix Released
|
Critical
|
Andy Whitcroft | ||
Bug Description
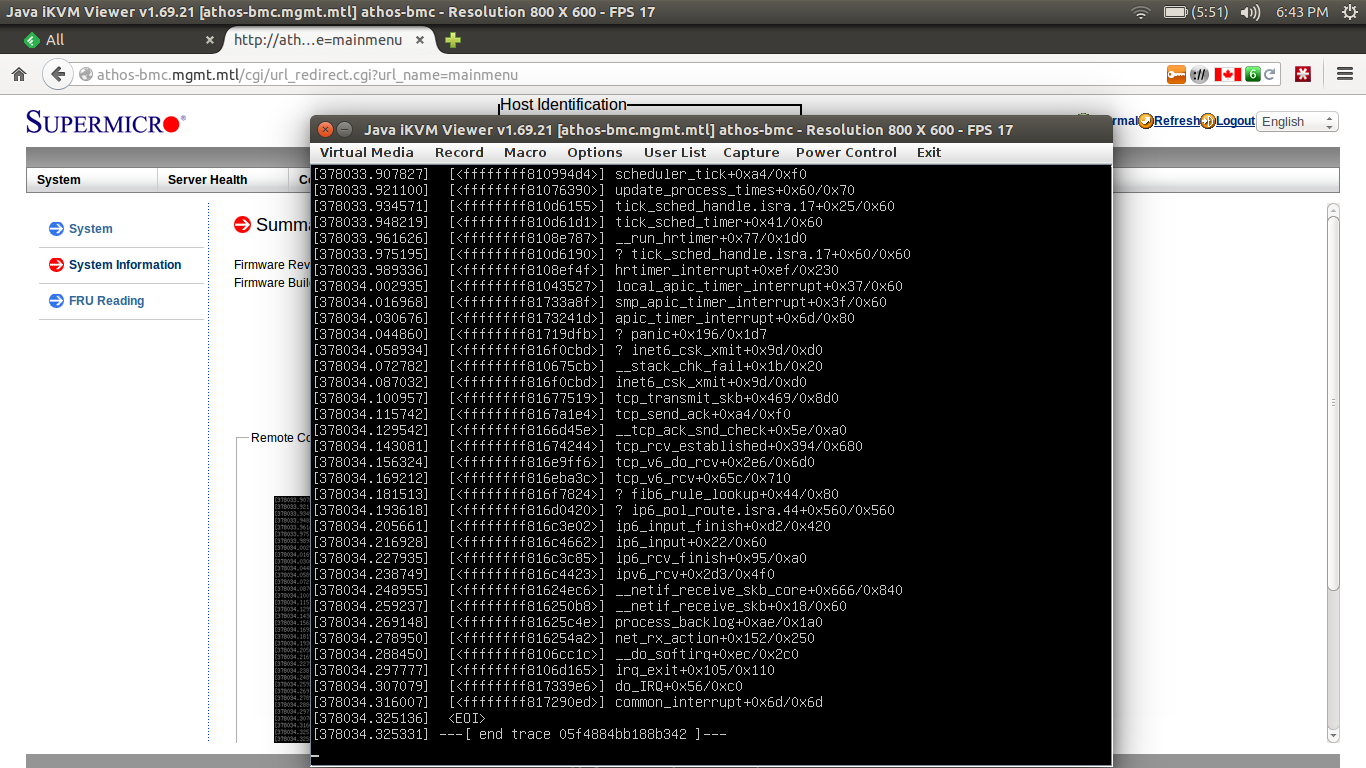
After updating a dozen machines from 3.13.0-40 to 3.13.0-43, they all kernel panic within the next 24 hours.
I managed to pull the console from one over an IP KVM and it shows a panic related to IPv6 networking:
https:/
All affected machines had native IPv6 connectivity to the Internet.
Downgrading to 3.13.0-40 resolved the issue (so it's clearly a regression) and upgrading to lts-utopic 3.16.0-28-generic also appeared to do the trick.
A friend also just reported seeing the exact same problem on his server which also has native IPv6 connectivity so the issue appears pretty widespread.

{kind=link}
| Changed in linux (Ubuntu): | |
| status: | Incomplete → Confirmed |
| Changed in linux (Ubuntu): | |
| importance: | Undecided → Critical |
| tags: | added: kernel-key trusty |
{kind=link}
| Changed in linux (Ubuntu): | |
| assignee: | nobody → Andy Whitcroft (apw) |
| milestone: | none → ubuntu-15.01 |
| Changed in linux (Ubuntu Trusty): | |
| status: | New → In Progress |
| importance: | Undecided → Critical |
| assignee: | nobody → Andy Whitcroft (apw) |
| tags: |
added: kernel-da-key removed: kernel-key |
| Changed in linux (Ubuntu Trusty): | |
| status: | In Progress → Fix Committed |
| Changed in linux (Ubuntu Trusty): | |
| status: | Fix Released → Fix Committed |
| tags: | removed: verification-done-trusty |
To post a comment you must log in.
Might be worth mentioning that all affected hosts are x86 64bit Intel.
For those I've got access to, the issue happened on:
- 2x Xeon E3-1245v2
- 1x Xeon E5-2620v2
- 1x Atom C2750
- 1x Atom D2500
- 1x Core i5 750
All running on pretty standard Intel boards, so the usual set of Intel chipsets for their generation.